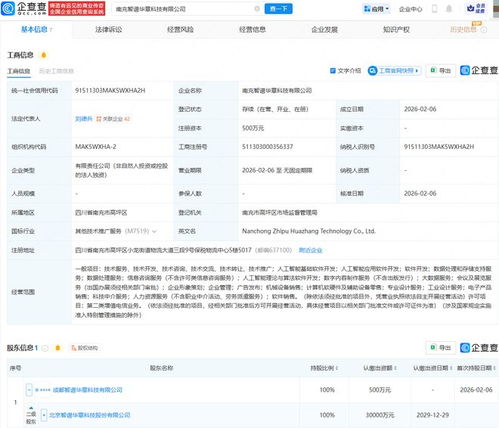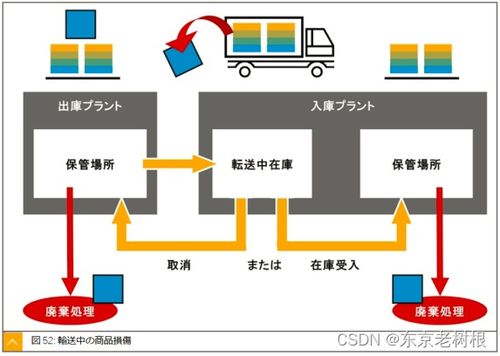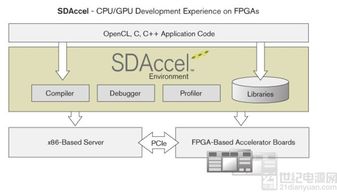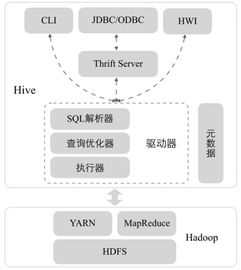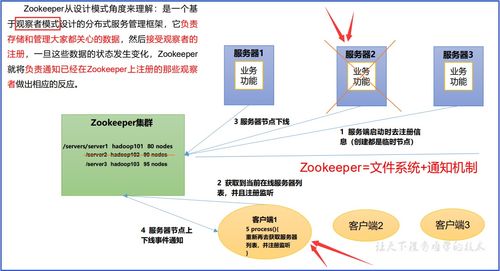
ZooKeeper是一个分布式的、开源的协调服务框架,广泛应用于分布式系统中。它通过简单的数据模型和API,为分布式应用提供一致性和可靠性保障。
一、ZooKeeper工作机制
ZooKeeper采用主从架构,其中包含一个Leader节点和多个Follower节点。客户端可以连接到任意节点进行读写操作。工作机制主要包括以下几个方面:
- 选举机制:当Leader节点失效时,Follower节点通过Zab协议进行选举,选出新的Leader。
- 请求处理:写请求由Leader处理,通过两阶段提交确保数据一致性;读请求可以由任意节点处理,提高性能。
- 数据同步:Leader节点将写操作广播给Follower,确保所有节点数据一致。
- 会话管理:客户端与ZooKeeper建立会话,通过心跳机制维持连接,超时则会话失效。
二、ZooKeeper特点
ZooKeeper具有以下显著特点:
- 顺序一致性:客户端的操作按顺序执行。
- 原子性:更新操作要么成功,要么失败,没有中间状态。
- 单一系统映像:无论连接到哪个节点,客户端看到的数据视图都是一致的。
- 可靠性:一旦更新生效,数据将持久化,直到被覆盖。
- 实时性:在一定时间范围内,客户端能读到最新数据。
- 高可用性:通过多节点部署,避免单点故障。
三、ZooKeeper数据结构
ZooKeeper的数据模型类似于文件系统的树形结构,每个节点称为ZNode。ZNode具有以下特性:
- 路径:每个ZNode有唯一的路径,如
/app/service1。 - 数据存储:ZNode可以存储少量数据(默认不超过1MB)。
- 节点类型:
- 持久节点:创建后一直存在,直到显式删除。
- 临时节点:与客户端会话绑定,会话结束则节点自动删除。
- 顺序节点:节点名会自动附加单调递增的序列号。
- 版本控制:每个ZNode有数据版本和子节点版本,用于乐观锁控制。
四、ZooKeeper提供的服务
ZooKeeper提供多种核心服务,支持分布式系统开发:
- 命名服务:通过ZNode路径实现服务注册与发现。
- 配置管理:将配置信息存储在ZNode中,客户端监听变化以实现动态配置更新。
- 集群管理:通过临时节点监控节点状态,实现故障检测和主节点选举。
- 分布式锁:利用ZNode的排他性实现互斥锁,或通过顺序节点实现公平锁。
- 队列管理:通过顺序节点实现先进先出队列或屏障同步。
五、数据处理服务
在数据处理方面,ZooKeeper提供以下功能:
- 数据发布/订阅:客户端可以监听ZNode的数据变化,当数据更新时接收通知。
- 数据一致性保证:通过Zab协议确保所有节点数据一致。
- 事务支持:ZooKeeper支持原子性操作,多个操作可以封装为一个事务。
- 数据持久化:数据会持久化到磁盘,同时内存中维护数据树以提高性能。
- 数据监控:通过Watch机制,客户端可以监控ZNode的创建、删除、数据变更等事件。
ZooKeeper作为分布式系统的协调核心,以其可靠性和简单性成为众多大型系统的基石。理解其工作机制、特点、数据结构和服务,对于设计和开发分布式应用至关重要。